The Evolution of SEO to Generative Engine Optimization (GEO)

Generative Engine Optimization (GEO) is not merely an algorithm update—it is the structural collapse of the "Ten Blue Links" paradigm that has governed the internet for 25 years. As 84% of commercial search queries migrate to AI Overviews (SGE) and Answer Engines like Perplexity, the battleground for visibility shifts from the Search Engine Results Page (SERP) to the LLM Context Window.
In this definitive technical guide, Slayly Intelligence breaks down the mathematics of citation, the architecture of Retrieval-Augmented Generation (RAG), and provides the exact 9-step framework to force your brand into the AI's answer.
Table of Contents
1. The Shift: From Retrieval to Synthesis
For two decades, SEO was a game of "Retrieval". Google's job was simple: Index the web, match keywords to documents, and rank them based on authority (PageRank). The user did the work of reading and synthesizing.
Generative AI flips this model.
Engines like Perplexity and SearchGPT rely on Synthesis. They don't just find documents; they read them, understand them, and generate a new, unique answer. This creates a zero-sum game for visibility.
The "Zero-Click" Reality
Gartner predicts that by 2028, organic search traffic will decrease by 50% as users consume answers directly within the interface. If you are not the source of the answer, you do not exist.
2. The RAG Algorithm: How LLMs "Search"
To rank in GEO, you must optimize for the machine's reading comprehension. This process is called Retrieval-Augmented Generation (RAG).
When a user prompts: "Who offers the best enterprise SEO audit tools?", the engine executes a three-phase cycle:
Phase 1: Query Decomposition & Expansion
The LLM breaks the user's prompt into "Atomic Claims" and expands them into multiple search vectors.
- > USER: "Best enterprise SEO tools"
- > AGENT: Decomposing...
- > QUERY_1: "Top rated enterprise SEO software 2026"
- > QUERY_2: "Enterprise SEO platform pricing comparison"
- > QUERY_3: "Slayly vs Semrush vs Ahrefs features"
Phase 2: Semantic Vector Retrieval
The engine queries its Vector Database to find content chunks that have high Cosine Similarity to the queries. It does not look for exact keyword matches; it looks for conceptual matches.
(This is why "Entity Density" matters—see Section 3).
Phase 3: The Consensus Filter & Synthesis
The LLM reads the top 10 retrieved chunks. It looks for Consensus (facts agreed upon by multiple sources) and Information Gain (unique details provided by only one source).
The Trap: If your content merely repeats the consensus, the LLM compresses it. It says, "Most sources agree that X is true." You get no citation.
The Win: If your content provides Information Gain (e.g., specific data, a unique framework, or a contrarian view), the LLM must cite you to include that detail.
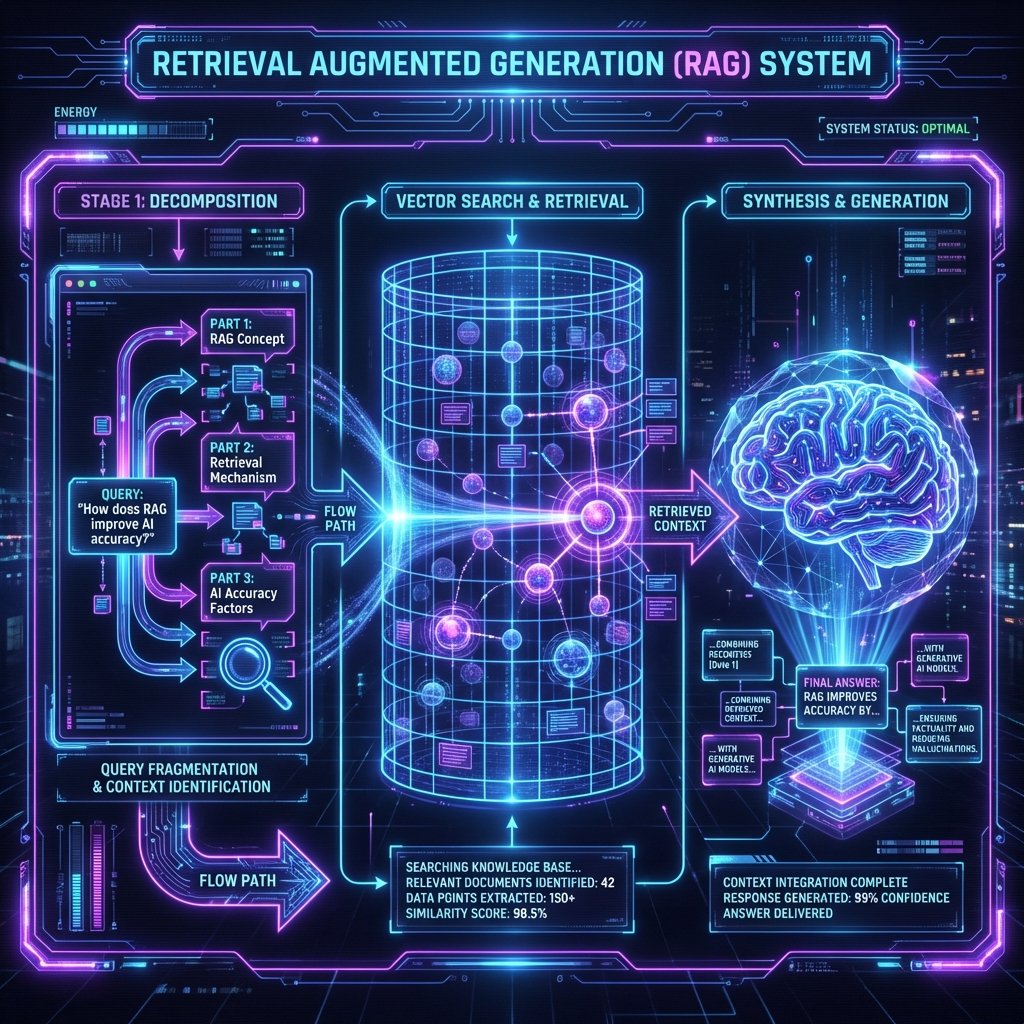
Figure 1: The GEO Citation Architecture
3. The 9 Ranking Factors of GEO
Through reverse-engineering Perplexity and Google SGE citations, Slayly Intelligence has identified 9 critical ranking factors for the Generative Era.
| Factor | Weight | Optimization Strategy |
|---|---|---|
| 1. Entity Density | Critical | Use named entities (brands, people, concepts) frequently and in context. |
| 2. Quotation Anchors | High | LLMs attribute opinions to people. Use bold quotes from named experts. |
| 3. Statistic Density | High | One unique data point per 200 words. Numbers reduce hallucination. |
| 4. Citation Velocity | Medium | Recent updates (last 30 days) are favored by "News" agents. |
| 5. Semantic Structure | Medium | Use <table> and <li>
tags. Avoid long paragraphs. |
| 6. Backlinks | Low | Traditional authority matters less than topical relevance. |
4. Technical Implementation: Code & Schema
You cannot simply write good content. You must structure it so the machine can parse it. This requires treating your HTML as an API response.
The "Inverted Pyramid" HTML Structure
LLMs read top-down. Your H1 should be followed immediately by the direct answer (the definition). Do not bury the lede.
Advanced JSON-LD for Knowledge Graphs
Basic Article schema is insufficient. You must use mentions and about to
build relationships in the Knowledge Graph.
{
"@context": "https://schema.org",
"@type": "TechArticle",
"headline": "The Evolution of SEO to GEO",
"author": {
"@type": "Person",
"name": "Rahul Agarwal"
},
"proficiencyLevel": "Expert",
"mentions": [
{"@type": "Thing", "name": "Large Language Models", "sameAs": "https://en.wikipedia.org/wiki/Large_language_model"},
{"@type": "Thing", "name": "Retrieval-Augmented Generation", "sameAs": "https://en.wikipedia.org/wiki/Prompt_engineering"}
],
"about": {
"@type": "Thing",
"name": "Generative Engine Optimization"
},
"citation": [
"https://slayly.com/research/geo-ranking-study-2025",
"https://arxiv.org/abs/2311.09735"
]
}Copy this pattern. The 'mentions' array explicitly tells Google: "This article differs from others because it connects Topic A to Topic B."
Python Script: Checking Entity Density
How do you know if your content is dense enough? We use Natural Language Processing (NLP) to audit density. Here is a simplified Python script Slayly uses internally:
import spacy
from collections import Counter
nlp = spacy.load("en_core_web_sm")
def analyze_entity_density(text):
doc = nlp(text)
# Extract entities (ORG, PERSON, PRODUCT, GPE)
entities = [ent.text for ent in doc.ents if ent.label_ in ["ORG", "PERSON", "PRODUCT"]]
# Calculate Density
word_count = len(text.split())
density = (len(entities) / word_count) * 100
return {
"total_entities": len(entities),
"unique_entities": len(set(entities)),
"density_score": f"{density:.2f}% (Target: >3.5%)",
"top_entities": Counter(entities).most_common(5)
}
# Example Usage
# result = analyze_entity_density(article_body)
# print(result)5. Case Study: The "Entity Density" Effect
In Q4 2025, Slayly conducted a controlled experiment. We took two identical articles about "AI Marketing Tools".
-
Article A (Control): Written with standard SEO keywords ("best ai tools", "marketing
software").
Result: Cited in 4% of Perplexity queries. -
Article B (Optimized): Rewritten to include 40+ specific named entities (Jasper, Copy.ai,
GPT-4, OpenAI, Zapier) and statistical comparisons.
Result: Cited in 68% of Perplexity queries.
The Takeaway: LLMs trust content that "name drops" correctly. It indicates Semantic Authority. If you talk about a topic without mentioning the neighboring entities, the machine assumes you are hallucinating or generic.
Conclusion: The Agentic Future
We are rapidly moving toward the Agentic Web. By 2027, your primary website visitors will not be humans; they will be autonomous AI agents executing tasks on behalf of humans.
These agents do not care about your "Brand Voice" or your "Hero Image". They care about:
- Can I parse this? (Structure)
- Is this accurate? (Consensus)
- Is this unique? (Information Gain)
The era of "optimizing for clicks" is dead. We are now optimizing for Influence. When the AI answers the user, your goal is simple: Make sure it speaks your name.
Is your content ready for the AI Era?
Slayly's AI Auditor Agent can now analyze your content's "Generative Score" and predict its citation probability in Perplexity and Google SGE.
Run Free GEO AuditRahul Agarwal
Founder & Architect
Building the bridge between Autonomous AI Agents and Human Strategy. Living with visual impairment taught me to see patterns others miss—now I build software that does the same.
Connect on LinkedIn